Jeffreys prior
In Bayesian probability, the Jeffreys prior, named after Harold Jeffreys, is a non-informative (objective) prior distribution on parameter space that is proportional to the square root of the determinant of the Fisher information:
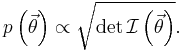
It has the key feature that it is invariant under reparameterization of the parameter vector 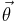 . This makes it of special interest for use with scale parameters.[1]
. This makes it of special interest for use with scale parameters.[1]
Contents |
Reparameterization
For an alternate parameterization 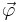 we can derive
we can derive
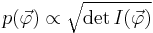
from
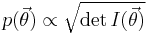
using the change of variables theorem, the definition of Fisher information, and that the product of determinants is the determinant of the matrix product:
![\begin{align}
p(\vec\varphi) & = p(\vec\theta) \left|\det\frac{\partial\theta_i}{\partial\varphi_j}\right| \\
& \propto \sqrt{\det I(\vec\theta)\, {\det}^2\frac{\partial\theta_i}{\partial\varphi_j}} \\
& = \sqrt{\det \frac{\partial\theta_k}{\partial\varphi_i}\, \det \operatorname{E}\!\left[\frac{\partial \ln L}{\partial\theta_k} \frac{\partial \ln L}{\partial\theta_l} \right]\, \det \frac{\partial\theta_l}{\partial\varphi_j}} \\
& = \sqrt{\det \operatorname{E}\!\left[\sum_{k,l} \frac{\partial\theta_k}{\partial\varphi_i} \frac{\partial \ln L}{\partial\theta_k} \frac{\partial \ln L}{\partial\theta_l} \frac{\partial\theta_l}{\partial\varphi_j} \right]} \\
& = \sqrt{\det \operatorname{E}\!\left[\frac{\partial \ln L}{\partial\varphi_i} \frac{\partial \ln L}{\partial\varphi_j}\right]}
= \sqrt{\det I(\vec\varphi)}.
\end{align}](/2012-wikipedia_en_all_nopic_01_2012/I/03165412c3d3dd5c34289140851636b5.png)
In the simpler case of a single parameter space variable we can derive
![\begin{align}
p(\varphi) & = p(\theta) \left|\frac{d\theta}{d\varphi}\right|
\propto \sqrt{\operatorname{E}\!\left[\left(\frac{d \ln L}{d\theta}\right)^2\right] \left(\frac{d\theta}{d\varphi}\right)^2} \\
& = \sqrt{\operatorname{E}\!\left[\left(\frac{d \ln L}{d\theta} \frac{d\theta}{d\varphi}\right)^2\right]}
= \sqrt{\operatorname{E}\!\left[\left(\frac{d \ln L}{d\varphi}\right)^2\right]}
= \sqrt{I(\varphi)}.
\end{align}](/2012-wikipedia_en_all_nopic_01_2012/I/6f654d2b8136172a201b706ebaa63393.png)
Attributes
From a practical and mathematical standpoint, a valid reason to use this non-informative prior instead of others, like the ones obtained through a limit in conjugate families of distributions, is that it is not dependent upon the set of parameter variables that is chosen to describe parameter space.
Sometimes the Jeffreys prior cannot be normalized, and thus one must use an improper prior. For example, the Jeffreys prior for the distribution mean is uniform over the entire real line in the case of a Gaussian distribution of known variance.
Use of the Jeffreys prior violates the strong version of the likelihood principle, which is accepted by many, but by no means all, statisticians. When using the Jeffreys prior, inferences about depend not just on the probability of the observed data as a function of , but also on the universe of all possible experimental outcomes, as determined by the experimental design, because the Fisher information is computed from an expectation over the chosen universe. Accordingly, the Jeffreys prior, and hence the inferences made using it, may be different for two experiments involving the same parameter even when the likelihood functions for the two experiments are the same—a violation of the strong likelihood principle.
Minimum description length
In the minimum description length approach to statistics the goal is to describe data as compactly as possible where the length of a description is measured in bits of the code used. For a parametric family of distributions one compares a code with the best code based on one of the distributions in the parameterized family. The main result is that in exponential families, asymptotically for large sample size, the code based on the distribution that is a mixture of the elements in the exponential family with the Jeffreys prior is optimal. This result holds if one restricts the parameter set to a compact subset in the interior of the full parameter space. If the full parameter is used a modified version of the result should be used.
Examples
The Jeffreys prior for a parameter (or a set of parameters) depends upon the statistical model.
Gaussian distribution with mean parameter
For the Gaussian distribution of the real value 
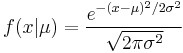
the Jeffreys prior for the mean 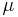 is
is
![\begin{align} p(\mu) & \propto \sqrt{I(\mu)}
= \sqrt{\operatorname{E}\!\left[ \left( \frac{d}{d\mu} \log f(x|\mu) \right)^2\right]}
= \sqrt{\operatorname{E}\!\left[ \left( \frac{x - \mu}{\sigma^2} \right)^2 \right]} \\
& = \sqrt{\int_{-\infty}^{%2B\infty} f(x|\mu) \left(\frac{x-\mu}{\sigma^2}\right)^2 dx}
= \sqrt{\frac{\sigma^2}{\sigma^4}}
\propto 1.\end{align}](/2012-wikipedia_en_all_nopic_01_2012/I/147f4c417e7402e082ffbe3082f12433.png)
That is, the Jeffreys prior for is the unnormalized uniform distribution on the real line — the distribution that is 1 (or some other fixed constant) for all points. This is an improper prior, and is, up to the choice of constant, the unique translation-invariant distribution on the reals (the Haar measure with respect to addition of reals), corresponding to the mean being a measure of location and translation-invariance corresponding to no information about location.
Gaussian distribution with standard deviation parameter
For the Gaussian distribution of the real value

the Jeffreys prior for the standard deviation σ > 0 is
![\begin{align}p(\sigma) & \propto \sqrt{I(\sigma)}
= \sqrt{\operatorname{E}\!\left[ \left( \frac{d}{d\sigma} \log f(x|\sigma) \right)^2\right]}
= \sqrt{\operatorname{E}\!\left[ \left( \frac{(x - \mu)^2-\sigma^2}{\sigma^3} \right)^2 \right]} \\
& = \sqrt{\int_{-\infty}^{%2B\infty} f(x|\mu)\left(\frac{(x-\mu)^2-\sigma^2}{\sigma^3}\right)^2 dx}
= \sqrt{\frac{2}{\sigma^2}}
\propto \frac{1}{\sigma}.
\end{align}](/2012-wikipedia_en_all_nopic_01_2012/I/32c461c42f9d557cf755c6562bf4b44b.png)
Equivalently, the Jeffreys prior for log σ2 (or log σ) is the unnormalized uniform distribution on the real line, and thus this distribution is also known as the logarithmic prior. It is the unique (up to a multiple) prior (on the positive reals) that is scale-invariant (the Haar measure with respect to multiplication of positive reals), corresponding to the standard deviation being a measure of scale and scale-invariance corresponding to no information about scale. As with the uniform distribution on the reals, it is an improper prior.
Poisson distribution with rate parameter
For the Poisson distribution of the non-negative integer  ,
,
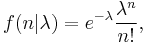
the Jeffreys prior for the rate parameter λ ≥ 0 is
![\begin{align}p(\lambda) &\propto \sqrt{I(\lambda)}
= \sqrt{\operatorname{E}\!\left[ \left( \frac{d}{d\lambda} \log f(x|\lambda) \right)^2\right]}
= \sqrt{\operatorname{E}\!\left[ \left( \frac{n-\lambda}{\lambda} \right)^2\right]} \\
& = \sqrt{\sum_{n=0}^{%2B\infty} f(n|\lambda) \left( \frac{n-\lambda}{\lambda} \right)^2}
= \sqrt{\frac{1}{\lambda}}.\end{align}](/2012-wikipedia_en_all_nopic_01_2012/I/7b55e995a68e31415011c501dc5c51db.png)
Equivalently, the Jeffreys prior for 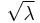 is the unnormalized uniform distribution on the non-negative real line.
is the unnormalized uniform distribution on the non-negative real line.
Bernoulli trial
For a coin that is "heads" with probability γ ∈ [0,1] and is "tails" with probability 1 − γ, for a given (H,T) ∈ {(0,1), (1,0)} the probability is 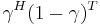 . The Jeffreys prior for the parameter
. The Jeffreys prior for the parameter 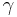 is
is
![\begin{align}p(\gamma) & \propto \sqrt{I(\gamma)}
= \sqrt{\operatorname{E}\!\left[ \left( \frac{d}{d\gamma} \log f(x|\gamma) \right)^2\right]}
= \sqrt{\operatorname{E}\!\left[ \left( \frac{H}{\gamma} - \frac{T}{1-\gamma}\right)^2 \right]} \\
& = \sqrt{\gamma \left( \frac{1}{\gamma} - \frac{0}{1-\gamma}\right)^2 %2B (1-\gamma)\left( \frac{0}{\gamma} - \frac{1}{1-\gamma}\right)^2}
= \frac{1}{\sqrt{\gamma(1-\gamma)}}\,.\end{align}](/2012-wikipedia_en_all_nopic_01_2012/I/62ad8a5f81378572caefbded58a4745d.png)
This is the arcsine distribution and is a beta distribution with 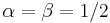 . Furthermore, if
. Furthermore, if 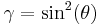 the Jeffreys prior for
the Jeffreys prior for 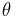 is uniform in the interval
is uniform in the interval ![[0, \pi / 2]](/2012-wikipedia_en_all_nopic_01_2012/I/df4639c5677b082cc59d25d1ae0f87e7.png) . Equivalently, is uniform on the whole circle
. Equivalently, is uniform on the whole circle ![[0, 2 \pi]](/2012-wikipedia_en_all_nopic_01_2012/I/58c9a5de0cb1a343ae0acd1fb191eea1.png) .
.
 -sided die with biased probabilities
-sided die with biased probabilities
Similarly, for a throw of an -sided die with outcome probabilities 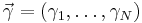 , each non-negative and satisfying
, each non-negative and satisfying 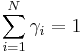 , the Jeffreys prior for
, the Jeffreys prior for 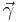 is the Dirichlet distribution with all (alpha) parameters set to
is the Dirichlet distribution with all (alpha) parameters set to 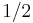 . In particular, if we write
. In particular, if we write 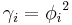 for each
for each  , then the Jeffreys prior for
, then the Jeffreys prior for 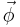 is uniform on the (N–1)-dimensional unit sphere (i.e., it is uniform on the surface of an N-dimensional unit ball).
is uniform on the (N–1)-dimensional unit sphere (i.e., it is uniform on the surface of an N-dimensional unit ball).
References
- Jeffreys, H. (1946). "An Invariant Form for the Prior Probability in Estimation Problems". Proceedings of the Royal Society of London. Series A, Mathematical and Physical Sciences 186 (1007): 453–461. doi:10.1098/rspa.1946.0056. JSTOR 97883.
- Jeffreys, H. (1939). Theory of Probability. Oxford University Press.